
Data is the core infrastructure of enterprise software. As enterprises adopt AI and data-driven workflows, the systems that collect, process, and govern data have become a primary source of competitive advantage. The “data layer” determines not just how software scales, but how effectively organizations generate insight, maintain compliance, and innovate. This layer is undergoing a structural shift. Cloud-native architectures, real-time and unstructured data, and AI workloads have transformed data infrastructure from a back-office function into a strategic control point across the enterprise
This research maps the Enterprise Data Layer end-to-end – from data generation and ingestion to storage, analytics, and governance – highlighting the technologies reshaping each segment, the operational challenges enterprises face, and the resulting investment opportunities.
The goal is simple: identify where value is being created today in the data stack, and where it will concentrate next as data becomes the foundation of enterprise software.
1. Data Generation & Labelling
Data is the fuel for AI models – a key layer in the stack determining model quality, safety, and scope. High-quality data is foundational for building large AI models. The performance of today’s advanced large language models (LLMs) depends heavily on the quality and scale of their training data. However, the push toward ever-larger models is outstripping the available supply of real-world, labelled data. The pool of usable internet data is running dry.
This scarcity has sparked solutions enabling companies to generate new synthetic data and unlock previously inaccessible unstructured data through automated data labelling.
1.1. Synthetic Data
Synthetic data has emerged as the structural remedy to the lack of real-world data: it delivers abundant, label-rich, and compliant datasets, allows edge case scenarios to be generated on-demand, and is available at a materially lower cost. By augmenting limited real datasets with extensive artificial examples, synthetic data enables continued performance improvements at scale without being bottlenecked by data scarcity.
Synthetic data is particularly valuable when real data is scarce, expensive, or sensitive (e.g. medical records or personal information) or where critical edge-case coverage and outcome diversity are key for the application (e.g. autonomous vehicles, healthcare). While powerful, synthetic data introduces risks including reduced realism, bias amplification, and potential model degradation when it substitutes too heavily for real-world data.
Market Dynamics:
The use of synthetic data has increased dramatically over the last few years as foundational models have continued to scale and increase in size, exhausting the supply of readily available real data. As models continue to scale, this trend is only likely to accelerate. (See illustration below)
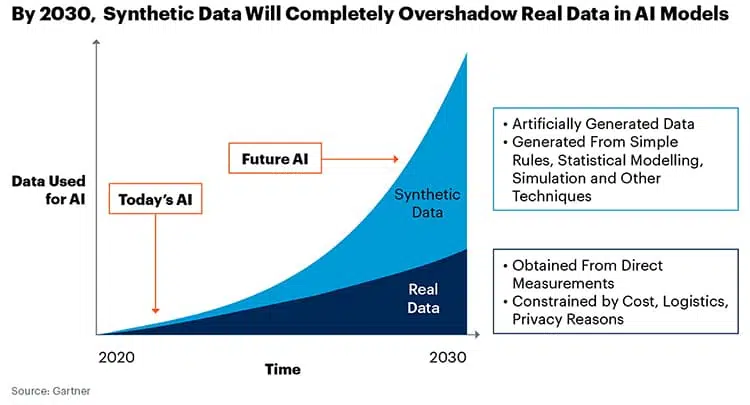
Several trends are shaping the synthetic data landscape:
- Vertical, closed-loop stacks: Startups are converging on domain-specific generators that encode industry edge cases and workflows, with vertical-first GTM and productised offerings (APIs, dataset packs, marketplaces).
- Multimodal by default: Modern pipelines span 3D, video, sensor, time-series, and tabular data – often built on digital twins or game engines to generate rare, safety-critical scenarios.
- Moats in governance and fidelity: Differentiation is shifting to coverage and realism metrics, privileged real-data access, time-to-coverage SLAs, and governance tooling (bias audits, collapse detection, traceability).
- Platforms over point solutions: Leading vendors are evolving from data providers into end-to-end platforms with coverage planning, controllable generation, auto-labelling, and quality scoring.
- Synthetic data as simulation infrastructure: Beyond training, synthetic data increasingly underpins simulation and experimentation – from clinical trials to marketing and software testing.
Notable Companies:
1.2 Data Labelling
Data labelling gives structure and meaning to raw data so models can learn. Early LLMs relied heavily on labelled examples for supervised learning and instruction tuning (clear input-output pairs that taught models how to follow tasks and reflect user intent).
High-quality annotation remains critical because it drives:
- Accuracy: Life-or-death distinctions, like telling a pedestrian from a traffic sign.
- Scale: Large labelled datasets make models more robust and performant.
- Adaptability: Good labels help models generalize and capture rare edge cases.
- Domain nuance: Legal, medical, and customer-support models need precise, contextual annotation.
- Safety: Labels underpin hallucination detection, evaluation, and alignment.
The bottleneck is supply. The world generates enormous amounts of unstructured text, images, and audio – but only a tiny share is clean, consistent, and usable for training. This gap created a market for specialist labelling firms that transform messy public data into training-ready datasets and help enterprises label proprietary data to ground their internal LLMs with domain-specific context.
Market Dynamics:
The category began as labour-intensive annotation work with large workforces tagging images, transcribing audio, and classifying text. Early providers solved a staffing and workflow problem: sourcing, coordinating, and quality-controlling a global annotator pool. Over time, they evolved into full data-operations platforms responsible for consistency, QA, and delivery of high-quality labelled data. Today, expectations have shifted again: providers are increasingly asked to integrate labelled datasets into model pipelines, becoming broader training-data infrastructure players.
The market is now shifting on two fronts:
- Automation: Routine labelling is being semi-automated through AI-assisted annotation, heuristics, and active learning-cutting cost and cycle time while preserving quality.
- Shift to High Skill Labour: Human work is moving from basic tagging to high-skill RLHF and preference modelling, where domain experts (clinicians, lawyers, bankers) shape model behaviour on specialised tasks.
Labelling has evolved from commodity annotation to a strategic data-operations layer that produces scarce, high-signal supervision for training, fine-tuning, and continuous improvement of both enterprise and frontier models. Beyond labelling data to feed directly into LLMs, enterprises are using AI-powered labelling solutions to create structured datasets from proprietary internal data (using tools like Encord) or to enrich datasets with publicly available sources (for example, automating CRM enrichment with tools like Kernel or Freckle).
2. Data Ingestion & Transformation
The ingestion and transformation layer moves raw data from source systems into analytics-ready formats within data warehouses and lakes. It includes the pipelines and tools that extract data, transform it, and load it for downstream use. As data volume, variety, and velocity have grown, this layer has evolved from batch ETL to cloud-native ELT, real-time streaming, and increasingly AI-assisted pipelines.
Three trends are reshaping the layer:
- ETL → ELT → Streaming as real-time use cases proliferate
- Unstructured data ingestion driven by AI workloads
- Intelligent pipelines with greater automation and adaptability
2.1 ETL → ELT → Streaming
From batch ETL to ELT:
Traditional ETL emerged when compute and storage were scarce, requiring data to be transformed before loading. With distributed systems (Hadoop, Spark) and cloud warehouses, ELT became viable: raw data is loaded first, then transformed in-warehouse. Lower storage costs and scalable compute made ELT more flexible and faster, establishing it as the backbone of the modern data stack. This model is tightly coupled with cloud platforms like Snowflake and BigQuery, and transformation tools such as dbt.
Rise of streaming data pipelines:
Real-time use cases—live analytics, personalization, fraud detection—have driven adoption of streaming architectures. Tools like Apache Kafka, Apache Flink, and Spark Streaming process continuous event streams from sources such as IoT devices, applications, and logs, delivering insights in seconds rather than hours.
Most modern architectures now combine batch and streaming pipelines, applying each where latency and cost trade-offs make sense.
Market dynamics:
The integration market is mature but rapidly shifting cloudward. Legacy vendors (Informatica, Talend, IBM) have been displaced or forced to modernize, while cloud-native ELT players like Fivetran and Matillion scaled quickly by focusing on simple, reliable ingestion into cloud warehouses. By the mid-2020s, ELT is largely replacing on-prem ETL.
Streaming is the fastest-growing segment. Kafka has become the default data backbone, with startups building higher-level abstractions on top: Glassflow (stream deduplication and joins for ClickHouse), Estuary (sub-second real-time pipelines), Quix (IoT and industrial streaming), and Tinybird (real-time analytics on ClickHouse).
Notable Companies:
2.2 Unstructured Data Transformation
IBM estimates that over 80% of enterprise data is unstructured, spanning documents, text, images, audio, video, logs, and social content. Historically, transformation pipelines focused on structured data, as unstructured processing relied on brittle NLP, OCR, and ML systems with limited accuracy. The rise of LLMs has materially improved extraction and understanding of unstructured data, unlocking use cases from AI search and copilots to compliance monitoring and document summarization.
Two dominant approaches have emerged to connect unstructured data to downstream systems:
Category 1, Extract-and-Structure Approach:Unstructured data is converted into structured formats (e.g. CSV, JSON) by extracting predefined fields before storage or analysis. Formerly known as IDP, this approach has evolved with LLMs to deliver higher accuracy and flexibility. Vendors like Unstructured, Rossum, and Graphlit preprocess documents, extract text and metadata, and map them into queryable schemas.
Category 2, Direct-Load with On-Demand Extraction:Unstructured content is stored in raw or semi-structured form and indexed in vector databases. Information is retrieved and interpreted at query time via LLMs, typically using RAG. This model avoids upfront structuring and is well-suited to search and Q&A use cases, as seen with Glean and Hebbia.
The optimal approach depends on the use case, particularly requirements around latency, accuracy, repeatability, and downstream system integration:
- Category 1:
- Advantages:
- Higher initial accuracy through specialized extraction models
- Explicit data validation and quality controls
- Better for compliance-heavy environments requiring audit trails
- Lower query-time latency since data is pre-structured
- More cost-effective for repeated queries on the same data
- Challenges:
- Requires upfront schema definition
- Less flexible for ad-hoc queries
- Additional preprocessing overhead
- Potential information loss during extraction
- Use cases: Excels in scenarios requiring high accuracy, regulatory compliance, and repeated queries, such as financial processing, invoice automation, and compliance-heavy industries like healthcare and insurance.
- Advantages:
- Category 2:
- Advantages:
- Maximum flexibility for diverse query patterns
- Preserves original document context
- No upfront schema requirements –
- Better for exploratory analysis and semantic search
- Easier to add new data sources
- Challenges:
- Higher query-time costs (LLM inference)
- Potential accuracy variability
- More challenging to ensure consistent results
- Harder to implement compliance controls
- Use cases: Dominates in knowledge work, research, and customer support scenarios where query patterns are unpredictable and semantic understanding is paramount: legal, customer success, research and knowledge search
- Advantages:
Notable Companies:
2.3 Intelligent Data Pipelines
Traditional data pipelines are manual and brittle: engineers write and maintain transformation code, manage schedules, debug failures, and resolve data quality issues by hand. Intelligent data pipelines aim to automate this lifecycle by embedding AI across development, testing, monitoring, and optimization—shifting from manual pipeline engineering to agentic data engineering. Vendors such as Monte Carlo, Bigeye, Soda Data, Great Expectations, Prophecy, and Mage are driving this transition.
Market dynamics cluster around four areas:
- Data Pipeline Observability:Platforms like Monte Carlo, Bigeye, and Soda Data monitor pipeline health (volume, schema, drift) and alert teams to costly failures.
- Automated Testing & CI/CD:Tools such as Great Expectations bring test-driven development to data, enabling automated quality gates and safer deployments.
- No-Code and AI-Assisted Pipeline Design:Vendors like Prophecy and Mage use visual builders and LLM copilots to generate and maintain pipeline code, dramatically reducing development time for standard use cases.
- Self-Optimizing Pipelines: Cloud services (AWS Glue, Azure Data Factory, GCP Dataflow) and startups like Upsolver, Ascend.io, and Nexla automate scaling, schema evolution, performance tuning, and failure recovery.
Most tools remain point solutions, strong in one layer of the pipeline lifecycle. As with DevOps, we expect consolidation toward a small number of platforms that unify orchestration, observability, and AI-assisted development into a single workflow.
Notable Companies:
3. Data Storage
The data storage layer is the foundation of modern data infrastructure, spanning warehouses, lakes, and specialized databases. As data volumes and formats grow—and AI becomes embedded across products and operations—storage must support unstructured data, real-time access, and tight integration with ML pipelines. Traditional databases built for structured reporting are no longer sufficient.
This shift has driven two core architectural responses:
- Vector databases, which store and search unstructured data via embeddings, enabling semantic search, retrieval, and AI-native applications.
- Lakehouse architectures, which unify data lakes and warehouses into a single, scalable foundation for analytics and AI, enabled by open formats such as Delta Lake and Apache Iceberg.
The data storage layer has evolved in response to rising scale, complexity, and performance demands. Early systems centered on relational databases, optimized for structured, transactional workloads with ACID (atomicity, consistency, isolation, durability) guarantees. As applications scaled and data became more heterogeneous, distributed SQL and NoSQL databases emerged to support flexibility and web-scale use cases.
The explosion of data volume then drove the split between data warehouses (optimized, governed analytics) and data lakes (cheap, schema-less storage). This separation added operational complexity, prompting the rise of the lakehouse: a unified architecture combining warehouse reliability with lake-scale economics, enabled by formats like Delta Lake and Apache Iceberg.
Today, AI workloads are reshaping the stack again. Lakehouses have become the system of record, complemented by purpose-built databases—notably vector databases—to support real-time, unstructured, and AI-native workloads.
3.1 Vector Databases
Vector databases store data as high-dimensional embeddings, enabling semantic similarity search rather than exact-match queries. They are now core AI infrastructure, powering use cases such as semantic search, recommendations, and Retrieval-Augmented Generation (RAG) by grounding model outputs in relevant enterprise data. Gartner estimates that by 2026, over 30% of enterprises will use vector databases to augment AI models with proprietary data.
Market Dynamics:
The generative AI wave triggered rapid adoption and heavy funding – Weaviate, Zilliz (Milvus), and Pinecone raised significant capital, alongside projects like Qdrant and Chroma. However, vector search is quickly commoditizing as incumbents integrate it natively (e.g. AWS OpenSearch, PostgreSQL pgVector). As a result, standalone vector databases must differentiate on performance, scale, and advanced AI use cases.
Notable Companies:
3.2 Data Lakehouse
A data lakehouse unifies data lakes and warehouses by storing all raw data – structured, semi-structured, and unstructured – in low-cost cloud object storage. A transactional metadata layer adds warehouse features like schema enforcement, ACID transactions, and SQL analytics. This architecture solves the limitations of separate data lakes and warehouses: it combines cheap, scalable storage with fast queries and governance, enabling business intelligence, machine learning, and streaming analytics on a single platform without costly ETL pipelines or vendor lock-in.
Market Dynamics:
The data lakehouse has quickly moved from niche concept to mainstream architecture for large data platforms. Industry surveys show a surge in adoption and understanding over the past few years. In 2023, only a few organizations had deep lakehouse expertise; by 2025, over 38% reported a “detailed understanding” of lakehouse concepts – up from just 4% in 2023. A recent survey of enterprise data teams found that enabling AI use cases is now the top driver of data architecture investments. Over 85% of organizations have budgeted for and are implementing AI-ready data infrastructure, with the lakehouse identified as the strategic core.
There are three open table formats that power lakehouse technology: Apache Iceberg, Apache Hudi, and Delta Lake. Apache Iceberg has gained the most traction recently and is becoming the default format, primarily due to its vendor-neutral status under the Apache Foundation and superior performance. Major cloud providers (Snowflake, AWS, and GCP) have widely adopted it. Enterprises using Apache Iceberg benefit from the ability to move data between platforms without vendor lock-in. A rich ecosystem of startups like Dremio and Onehouse are building tools to optimize lakehouse storage cost and performance, especially for Iceberg. Meanwhile, incumbents like Databricks (which coined the lakehouse term) and Snowflake are in a high-profile race to dominate the unified analytics market. Cloud giants AWS, Google, and Microsoft have all launched lakehouse offerings as well (Amazon Lake Formation, Google BigLake, and Microsoft Fabric) to blend lake and warehouse capabilities.
Notable Companies:
4. Data query & analysis
Enterprises manage two fundamentally different data types: unstructured content (documents, emails, PDFs, audio) and structured tables in warehouses and lakes. Historically, insight came almost entirely from structured data, as extracting value from unstructured content was manual, slow, and expensive.
Market Trends:
Vector stores deployed alongside lakes and lakehouses now index unstructured assets and semantically join them with relational data. Natural-language interfaces query across both, enabling analysis that is both statistically precise and contextually aware.
RAG has become the core data primitive: LLMs retrieve relevant enterprise content to ground answers in internal data. Leading systems such as Hebbia go beyond simple vector search, separating question understanding from retrieval and composing evidence across many documents with citations. In parallel, MCP has emerged as an AI-native query gateway—an open standard from Anthropic that securely exposes tools like SQL, vector search, and governed documents through a unified interface. Together, RAG and MCP enable AI-native agents that turn fragmented enterprise knowledge into executable workflows.
The application layer is shifting from passive Q&A to agentic execution. With MCP, applications can retrieve data and take actions across systems (e.g. drafting contracts, updating CRMs). As a result, winners are moving beyond narrow RAG point solutions toward vertical platforms that automate end-to-end workflows and produce domain-specific outputs.
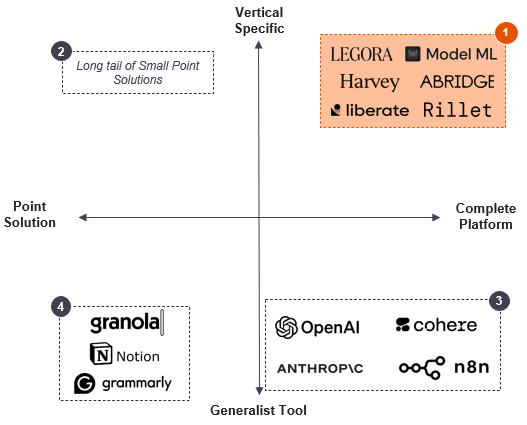
Four models coexist:
- Vertical Platform: Purpose-built platforms with wide ranging AI features to automate a wide variety of a given verticals workflows
- Point Solution: Target specific pain points in vertical workflow but lack breadth or interoperability across workflows
- Foundation Models & General Tools: Generalist AI platforms offer flexible capabilities but require heavy customisation for vertical precision; though foundation models are starting to train for vertical use cases (e.g. OpenAI for financial modelling use cases)
- General Productivity Point Solutions: Horizontal AI tools solve narrow tasks common to all firms (e.g. note taking / search) but lack domain context and integration depth
Enterprises increasingly prefer vertical platforms, driven by consolidation benefits, tighter integrations, and higher output quality. While generalist tools handle simple tasks, complex workflows demand domain accuracy, workflow-native design, expert account management, and flexible model choice.
This has fueled rapid adoption of vertical AI platforms such as Luminance, Harvey and Legora (legal), Model ML and Rillet (finance), Abridge (healthcare), and Liberate (insurance). Their moat combines proprietary retrieval, domain-tuned models, and generation optimized for industry-specific accuracy and formats.
Looking ahead, differentiation will shift from capability to cost and latency. As buyers compare AI apps against each other—not against humans—winners will optimize aggressively through model routing, context caching, and efficient retrieval. Providers that fail to do so will see margins compress as customers demand faster responses and lower cost per task.
Notable Companies:
5. Data Governance
The data governance layer for enterprise AI has evolved rapidly over the past decade, unfolding in three waves:
- Pre–Gen AI governance, centered on cataloging and control
- Gen AI–driven transformation, expanding governance to unstructured data and models
- AI/ML security and agentic compliance, addressing the risks of autonomous systems
Across the last two waves, governance has expanded well beyond lineage and cataloging to include model transparency, data ethics, cross-border sovereignty, and real-time monitoring of data usage and quality.
5.1 Pre-GenAI
Legacy platforms such as Collibra, Alation, and BigID established the foundations of enterprise data governance through catalogs, lineage, stewardship, and policy enforcement. While effective for BI and warehouse-centric stacks, these systems struggled to scale with cloud-native data sprawl and emerging AI workloads.
5.2 The GenAI Transformation
Generative AI fundamentally changed governance requirements. Enterprises now needed to govern unstructured data, vector stores, models, and LLM pipelines—often in real time. This drove demand for:
- AI-driven automation in discovery, classification, and anomaly detection
- Collaborative governance spanning legal, compliance, product, and data teams
- Regulatory agility to adapt to fast-changing privacy and AI regulations
Platforms like Atlan and Alation have embedded these capabilities, while BigID expanded into DSPM, unifying security, privacy, and compliance across traditional and AI-native data assets.
5.3 AI/ML Security & Agentic Compliance
Since 2022, a new class of AI/ML-native governance platforms has emerged, focused on securing AI systems themselves. These tools address:
- Model behavior monitoring, including drift, bias, hallucinations, and attacks
- Agentic lineage and auditability, as AI agents continuously ingest and generate data
Together, these platforms enable continuous governance across AI pipelines—combining security, compliance, and ethics while preserving the speed required for enterprise AI deployment.
Notable Companies:
6. Conclusion
In conclusion, as AI becomes embedded in every workflow, the battle moves down-stack: the winners will be the companies that control data quality, governance, and integration—not those with marginally better models. The enterprise data layer is consolidating into fewer, broader platforms designed to deliver measurable work products under compliance constraints.
- Data is the durable moat: Proprietary data + synthetic edge-case coverage + lineage + eval systems > model novelty.
- Consolidation gravity: Orchestration, observability, governance, and eval are bundling; standalone tools become features.
- Outcome > capability: Procurement shifts toward applications that ship completed outputs with audit trails and SLAs.
- Lakehouse backbone: Iceberg-led open table formats are becoming the neutral substrate for GenAI applications.
- HITL up-market: Differentiation moves to expert feedback, rules, evaluation, and governance—not cheap annotation.





